Page Last Updated: November 28, 2025
Tabulated Data🔗
Tabulated data are participant-level summaries of HBCD Study instruments (behavior, biology, and environment), Demographics, and select file-based data. Files are stored under rawdata/phenotype/:
hbcd/
|__ rawdata/
|__ phenotype/
|__ sed_basic_demographics.* # Basic Demographics
|__ par_visit_data.* # Visit Information
|__ bio_biosample_<nails|urine>.* # Toxicology
|__ {instrument_name}.* # Instrument Data
Key features of tabulated data include:
- Table Organization: tables are organized following the BIDS standard so that data from different sources can be linked together by participant ID and visit number
- File Types: tables are available in both plain text (
.tsv) and Parquet (.parquet) format, with accompanying metadata that explains the contents of each table
Table Organization🔗
Following the BIDS standard, each table includes identifier columns for participant ID, visit number, and run number (when applicable) that allow you to link information between tables:
| Column Name | Definition | Example |
|---|---|---|
participant_id |
Unique identifier for a participant | sub-0123456789 |
session_id |
Unique identifier for session/visit number | ses-V01 |
run_id |
Unique identifier for run number - only present in tables derived from file-based data with multiple runs, e.g. for MRI acquisition | 1 |
File Types🔗
Tabulated data are available in two formats, plain text files (.tsv/.csv) and Parquet (.parquet) - see details below. Each data table also comes with a shadow matrix file (<instrument_name>_shadow.<tsv|parquet>), which has the same structure of the corresponding data table, but contains codes explaining why values are missing - see details below.
Plain Text vs. Parquet Files🔗
Tabulated data are provided in multiple formats to support a range of tools and user preferences. Plain text files (.tsv/.csv) are widely compatible and easy to open/inspect in Excel or text editors. Metadata (including column types, variable labels, categorical coding, etc.) is stored in separate .json files accompanying each plain text file. Apache Parquet, or simply Parquet (.parquet), is a modern, compressed columnar format optimized for analysis and large-scale data. Unlike plain text files, metadata is embedded directly in parquet files, ensuring correct data types and enabling efficient loading and analysis in Python or R.
Which format should I use?🔗
| Format | When to use | Advantages | Limitations |
|---|---|---|---|
| TSV/CSV | Quick inspection, spreadsheet use |
Easy to open Widely compatible format |
Large files load slowly Separate metadata (see Caution below) Selective column loading not supported |
| Parquet | Analysis in Python/R for large data |
Optimized for large-scale data Fast loading and smaller files Metadata embedded Ensures correctly specified data types Supports selective column loading (saves memory) |
Not easily viewable in Excel Not currently supported by BIDS |
Caution: Using Plain Text Files for Analysis🔗
Plain text formats like TSV/CSV can cause problems in large-scale analyses due to the fact that metadata is stored separately (in sidecar JSON files). Python, R, or other tools may make mistakes when importing the data. For example:
- Tools may misinterpret data types, e.g.,
0/1used for “Yes/No” may be read as numeric instead of categorical. - Columns with mostly missing values may be treated as empty if the first few rows contain no data.
We therefore recommend using Parquet files for analysis to avoid these issues, as the metadata is embedded directly. However, if you do choose to use TSV/CSV files for analysis: be sure to manually define column types during import using the sidecar JSON metadata files. Additionally, make sure to specify n/a as placeholder for missing values when reading in the .tsv files (HBCD uses this placeholder as recommended by the BIDS specification). We recommend using NBDCtools to automate this process - see documentation for the function read_dsv_formatted() here.
Working with Parquet in Python and R🔗
Loading parquet files in Python (polars or pandas module):
# Using `polars` module [RECOMMENDED]:
import polars as pl
parquet_df = pl.read_parquet("path/to/file.parquet")
# Using `pandas` module:
import pandas as pd
parquet_df = pd.read_parquet("path/to/file.parquet")
# Using `arrow` package:
library(arrow)
parquet_df <- read_parquet("path/to/file.parquet")
Shadow Matrices for Missing Data🔗
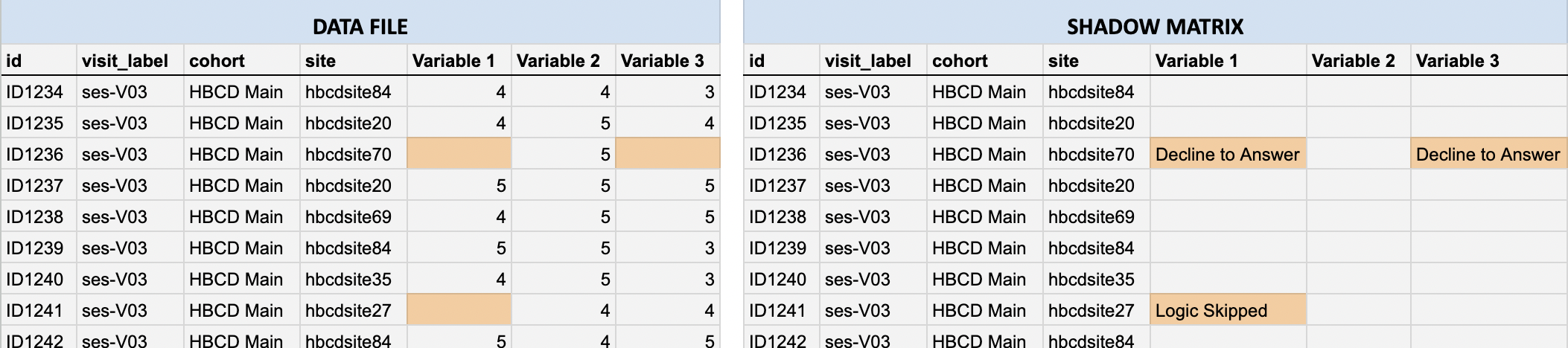
Each TSV or Parquet file in /rawdata/phenotype/ has a corresponding shadow matrix file in the same format that record the reason for missing values (e.g., Don't know, Decline to Answer, Logic Skipped, etc.) in the phenotype data.
How They Work🔗
In the data files, categorical codes for non-responses such as “Don’t know” (999) and “Decline to answer” (777) are deliberately converted to blank cells. The original responses are converted to a missingness reason stored in the shadow matrix, which mirror the structure and column names of the original data file (i.e. each cell corresponds to the same cell in the associated data file):
- If a data cell contains a value: the shadow matrix cell is blank.
- If a data cell is missing: the shadow matrix cell records the reason (e.g., “Don’t know”)
For example, compare the highlighted cells in the data file (left) vs. the corresponding shadow matrix (right) below:
Why Shadow Matrices Are Useful🔗
Shadow matrices make analyses cleaner and more reliable by:
- Preventing analytical errors, e.g., misinterpreting placeholder codes (like
777or999) as valid numbers. - Maintaining consistent data types across entries (e.g., avoids mixing text notes into numeric fields).
- Preserving non-response information without cluttering the main dataset.
Working with Shadow Matrices in Python and R🔗
While the approach of storing missingness reasons in a shadow matrix file supports cleaner analyses, there are situations where non-responses are themselves meaningful. For example, a researcher might be interested in how often participants do not understand a given question and how this relates to other variables. To understand patterns of missing data, users can re-integrate the non-responses from the shadow matrix back into the data using the following helper functions (click to expand):
import pandas as pd
import os
def load_data_with_shadow(data_path, shadow_path):
"""
Loads a data file (CSV or TSV) and its corresponding shadow matrix
(CSV or TSV) and adds '_missing_reason' columns for missing values.
"""
# Detect delimiter from file extension and load data
def get_delimiter(path):
ext = os.path.splitext(path)[1].lower()
return "\t" if ext == ".tsv" else ","
data = pd.read_csv(data_path, delimiter=get_delimiter(data_path))
shadow = pd.read_csv(shadow_path, delimiter=get_delimiter(shadow_path))
# Annotate data with non-empty missingness reason columns (excluding participant_id
# and session_id) in shadow matrix
for col in data.columns[2:]:
if col in shadow.columns:
if not shadow[col].isna().all() and not (shadow[col] == '').all():
data[f"{col}_missing_reason"] = shadow[col]
return data
# Example usage:
df = load_data_with_shadow("data.tsv", "shadow_matrix.tsv")
# Example: View reasons for missing data for a given column/variable in the data file
df[df["<COLUMN NAME>"].isna()][["<COLUMN NAME>_missing_reason"]]
library(dplyr)
library(NBDCtools)
# read in data and shadow matrix
data <- arrow::read_parquet("path/to/data/<table_name>.parquet")
shadow <- arrow::read_parquet("path/to/data/<table_name_shadow>.parquet")
# bind shadow columns to data
data_shadow <- shadow_bind_data(data, shadow)
# show the reasons for missing values for a given variable
data_shadow |>
filter(is.na(<column_name>)) |>
count(<column_name>)